
Author: Priyadharshini
A recent news item went as follows: “Apple buys machine learning firm Perceptio Inc., a startup, in an attempt to bring advanced image-classifying artificial intelligence to smartphones by reducing data overhead which is typically required of conventional methods.” Another recent development was that MIT researchers were working on object recognition through flexible machine learning.
Machine learning is starting to reshape how we live, and it’s time we understood what it is and why it matters.
Pro Tip: To fast-track your learning, consider Simplilearn’s comprehensive Machine Learning Advanced Certification Training. With modules in supervised and unsupervised learning, deep learning, Spark, and live industry projects, you can become a job-ready machine learning specialist in just a few weeks!
What is Machine Learning?
Machine learning is a core sub-area of artificial intelligence; it enables computers to get into a mode of self-learning without being explicitly programmed. When exposed to new data, these computer programs are enabled to learn, grow, change, and develop by themselves.
SAS, a North Carolina-based analytics software developer, uses this definition: “Machine learning is a method of data analysis that automates analytical model building.” In other words, it allows computers to find insightful information without being programmed where to look for a particular piece of information; instead, it does this by using algorithms that iteratively learn from data.
While the concept of machine learning has been around for a long time, (an early and notable example: Alan Turing’s famous WWII Enigma Machine) the ability to apply complex mathematical calculations to big data automatically—iteratively and quickly—has been gaining momentum over the last several years.
So, put simply, the iterative aspect of machine learning is the ability to adapt to new data independently. This is possible as programs learn from previous computations and use “pattern recognition” to produce reliable results.
Why Machine Learning?
To better understand the uses of machine learning, consider some of the instances where machine learning is applied: the self-driving Google car, cyber fraud detection, online recommendation engines—like friend suggestions on Facebook, Netflix showcasing the movies and shows you might like, and “more items to consider” and “get yourself a little something” on Amazon—are all examples of applied machine learning.
All these examples echo the vital role machine learning has begun to take in today’s data-rich world. Machines can aid in filtering useful pieces of information that help in major advancements, and we are already seeing how this technology is being implemented in a wide variety of industries.
The process flow depicted here represents how machine learning works

With the constant evolution of the field, there has been a subsequent rise in the uses, demands, and importance of machine learning. Big data has become quite a buzzword in the last few years; that’s in part due to increased sophistication of machine learning, which helps analyze those big chunks of big data. Machine learning has also changed the way data extraction, and interpretation is done by involving automatic sets of generic methods that have replaced traditional statistical techniques.
Uses Of Machine Learning
Earlier in this article, we mentioned some applications of machine learning. To understand the concept of machine learning better, let’s consider some more examples: web search results, real-time ads on web pages and mobile devices, email spam filtering, network intrusion detection, and pattern and image recognition. All these are by-products of applying machine learning to analyze huge volumes of data.
Traditionally, data analysis was always being characterized by trial and error, an approach that becomes impossible when data sets are large and heterogeneous. Machine learning comes as the solution to all this chaos by proposing clever alternatives to analyzing huge volumes of data. By developing fast and efficient algorithms and data-driven models for real-time processing of data, machine learning is able to produce accurate results and analysis.
Pro Tip: For more on Big Data and how it’s revolutionizing industries globally, check out our article about what Big Data is and why you should care.
The McKinsey report states, “As ever more of the analog world gets digitized, our ability to learn from data by developing and testing algorithms will only become more important for what are now seen as traditional businesses.” It also quotes Google’s chief economist Hal Varian who calls this “computer kaizen” and adds, “just as mass production changed the way products were assembled, and continuous improvement changed how manufacturing was done… so continuous (and often automatic) experimentation will improve the way we optimize business processes in our organizations.” It’s clear that machine learning is here to stay.
Terms and Types
Whether you realize it or not, machine learning is one of the most important technology trends—it underlies so many things we use today without even thinking about them. Speech recognition, Amazon and Netflix recommendations, fraud detection, and financial trading are just a few examples of machine learning commonly in use in today’s data-driven world.
Data Mining, Machine Learning, and Deep Learning
Put simply, machine learning and data mining use the same algorithms and techniques as data mining, except the kinds of predictions vary. While data mining discovers previously unknown patterns and knowledge, machine learning reproduces known patterns and knowledge—and further automatically applies that information to data, decision-making, and actions.
Deep learning, on the other hand, uses advanced computing power and special types of neural networks and applies them to large amounts of data to learn, understand, and identify complicated patterns. Automatic language translation and medical diagnoses are examples of deep learning.
Popular Machine Learning Methods
How exactly do machines learn? Two popular methods of machine learning are supervised learning and unsupervised learning. It is estimated that about 70 percent of machine learning is supervised learning, while unsupervised learning ranges from 10 – 20 percent. Other methods that are less-often used are semi-supervised and reinforcement learning.
Supervised Learning
This kind of learning is possible when inputs and the outputs are clearly identified, and algorithms are trained using labeled examples. To understand this better, let’s consider the following example: an equipment could have data points labeled F (failed) or R (runs).

The learning algorithm using supervised learning would receive a set of inputs along with the corresponding correct output to find errors. Based on these inputs, it would further modify the model accordingly. This is a form of pattern recognition, as supervised learning happens through methods like classification, regression, prediction, and gradient boosting. Supervised learning uses patterns to predict the values of the label on additional unlabeled data.
Supervised learning is more commonly used in applications where historical data predict future events, such as fraudulent credit card transactions.
Unsupervised Learning
Unlike supervised learning, unsupervised learning is used with data sets without historical data. An unsupervised learning algorithm explores surpassed data to find the structure. This kind of learning works best for transactional data; for instance, it helps in identifying customer segments and clusters with certain attributes—this is often used in content personalization.
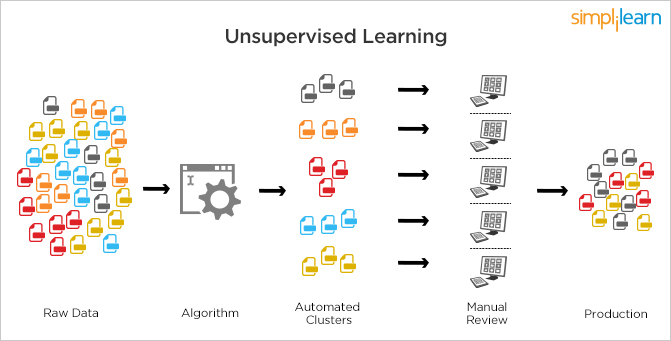
Popular techniques where unsupervised learning is used also include self-organizing maps, nearest neighbor mappig, singular value decomposition, and k-means clustering. Basically, online recommendations, identification of data outliers, and segment text topics are all examples of unsupervised learning.
Semi-Supervised Learning
As the name suggests, semi-supervised learning is a bit of both supervised and unsupervised learning and uses both labeled and unlabeled data for training. In a typical scenario, the algorithm would use a small amount of labeled data with a large amount of unlabeled data.

This type of learning can again be used with methods such as classification, regression, and prediction. Examples of semi-supervised learning would be face and voice recognition techniques.
Reinforcement Learning
This is a bit similar to the traditional type of data analysis; the algorithm discovers through trial and error and decides which action results in greater rewards. Three major components can be identified in reinforcement learning functionality: the agent, the environment, and the actions. The agent is the learner or decision-maker, the environment includes everything that the agent interacts with, and the actions are what the agent can do.

Reinforcement learning occurs when the agent chooses actions that maximize the expected reward over a given time. This is best achieved when the agent has a good policy to follow.
Some Machine Learning Algorithms And Processes
If you’re studying machine learning, you should familiarize yourself with these common machine learning algorithms and processes: neural networks, decision trees, random forests, associations and sequence discovery, gradient boosting and bagging, support vector machines, self-organizing maps, k-means clustering, Bayesian networks, Gaussian mixture models, and more.
Other tools and processes that pair up with the best algorithms to aid in deriving the most value from big data include:
- Comprehensive data quality and management
- GUIs for building models and process flows
- Interactive data exploration and visualization of model results
- Comparisons of different machine learning models to quickly identify the best one
- Automated ensemble model evaluation to identify the best performers
- Easy model deployment so you can get repeatable, reliable results quickly
- Integrated end-to-end platform for the automation of the data-to-decision process
Machine Learning caught your attention? Watch this course preview NOW!
What Is Artificial Intelligence and Why Gain a Certification in This Domain



